understand how Monte Carlo (MC) and Markov chain Monte Carlo (MCMC) methods differ
learn how to use MC methods to approximate posterior expectations and probabilities
understand how to sample from the posterior predictive distribution using MC methods
What we have seen in the last chapter up to now, is to use the conjugate prior to obtain closed form expressions for the posterior distribution. However, in many cases, conjugate priors are not available or not desirable. In such cases, we need to resort to numerical methods to approximate the posterior distribution.
Question.
How can we perform Bayesian inference when conjugate priors are not available and the posterior has no closed-form expression?
There are two broad classes of approaches:
Simulation-based methods:
accept–reject sampling, Markov chain Monte Carlo (MCMC), particle filters, and related algorithms.
Deterministic approximation methods:
Laplace approximations (including INLA), variational Bayes, expectation propagation, and related techniques.
We will be focusing on the Monte Carlo (MC) methods and its variation.
4.1 Overview
Monte Carlo
MC methods approximate expectations or probabilities using random sampling.
If samples can be drawn directly from the target distribution, Monte Carlo methods provide simple and effective estimators.
Typical use:
Numerical integration
Bootstrap methods
Simulation-based probability estimation
Markov Chain Monte Carlo
MCMC methods are used when direct sampling is infeasible. They construct a Markov chain whose stationary distribution is the target distribution, and use dependent samples from the chain after burn-in.
Typical use:
Bayesian posterior sampling
High-dimensional or unnormalized distributions
Gibbs Sampler
The Gibbs sampler is a special case of MCMC that samples sequentially from full conditional distributions. Because proposals are drawn exactly from conditionals, all updates are automatically accepted.
Typical use:
Bayesian hierarchical models
Models with conjugate full conditionals
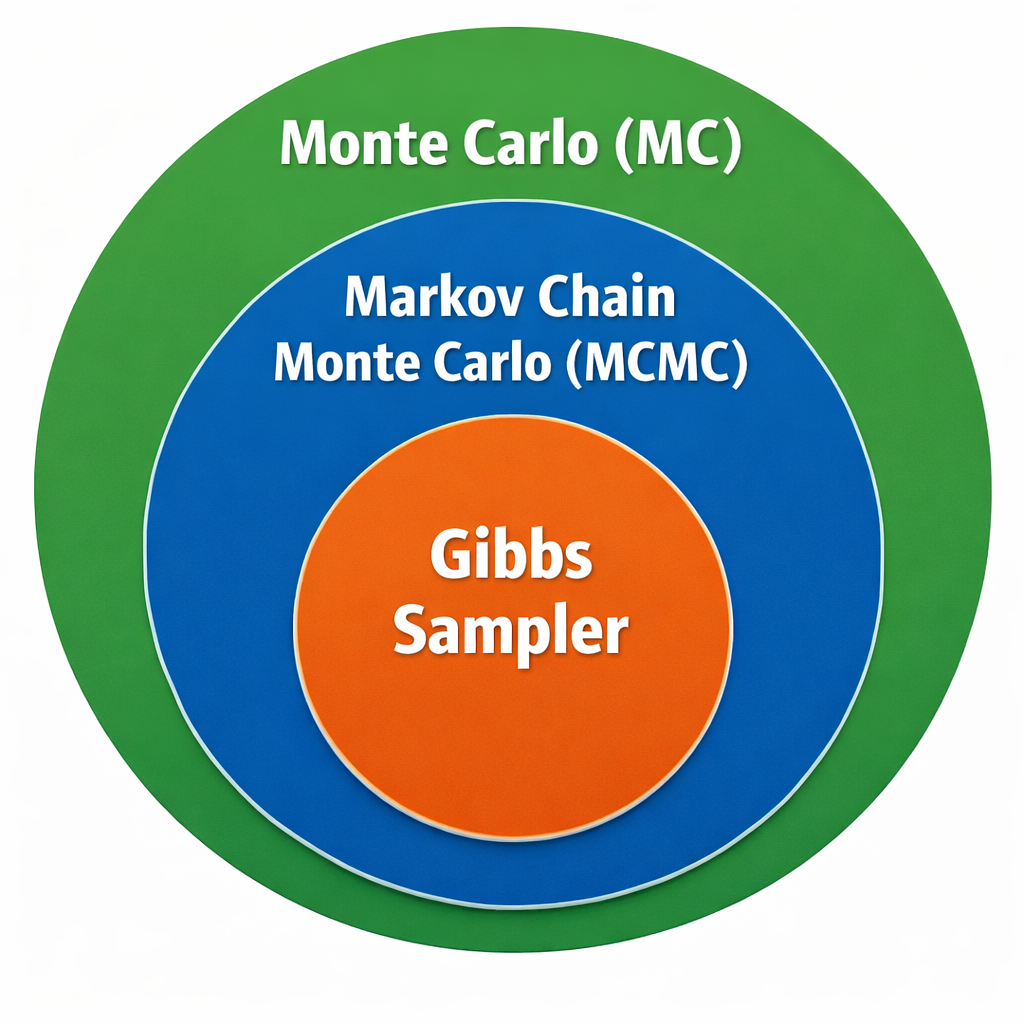
4.1.1 Relationship Between Monte Carlo, MCMC, and Gibbs Sampling
These three concepts are not competing methods, but rather form a nested hierarchy of ideas used for approximating expectations and probability distributions using randomness.
4.1.2 Summary Table
Method
Independent Samples
Uses Markov Chain
Accept–Reject Step
Typical Application
Monte Carlo
Yes
No
No
Direct simulation, integration
MCMC
No
Yes
Usually
Bayesian posterior sampling
Gibbs Sampler
No
Yes
No (always accept)
Bayesian models with tractable conditionals
NoteKey summary
MC is the general idea of using randomness for approximation.
MCMC is MC with dependent samples generated by a Markov chain.
Gibbs sampling is a specific MCMC algorithm based on full conditional distributions.
4.2 Monte Carlo Method
In the previous chapter, we obtained the following posterior distributions for the birth rates of women without and with bachelor’s degrees:
How do we compute such a probability? From the previous chapter, since \(\theta_1\) and \(\theta_2\) are conditionally independent given the data \(y\), we have \[
\Pr(\theta_1 > \theta_2 \mid y)
=
\int_0^\infty \int_0^{\theta_1}
p(\theta_1 \mid y)
p(\theta_2 \mid y)
\, d\theta_2 \, d\theta_1.
\]
This integral can be evaluated numerically. However, in realistic Bayesian models, such integrals quickly become high-dimensional and analytically intractable. This motivates Monte Carlo (MC) methods.
In Bayesian inference we repeatedly encounter integrals such as
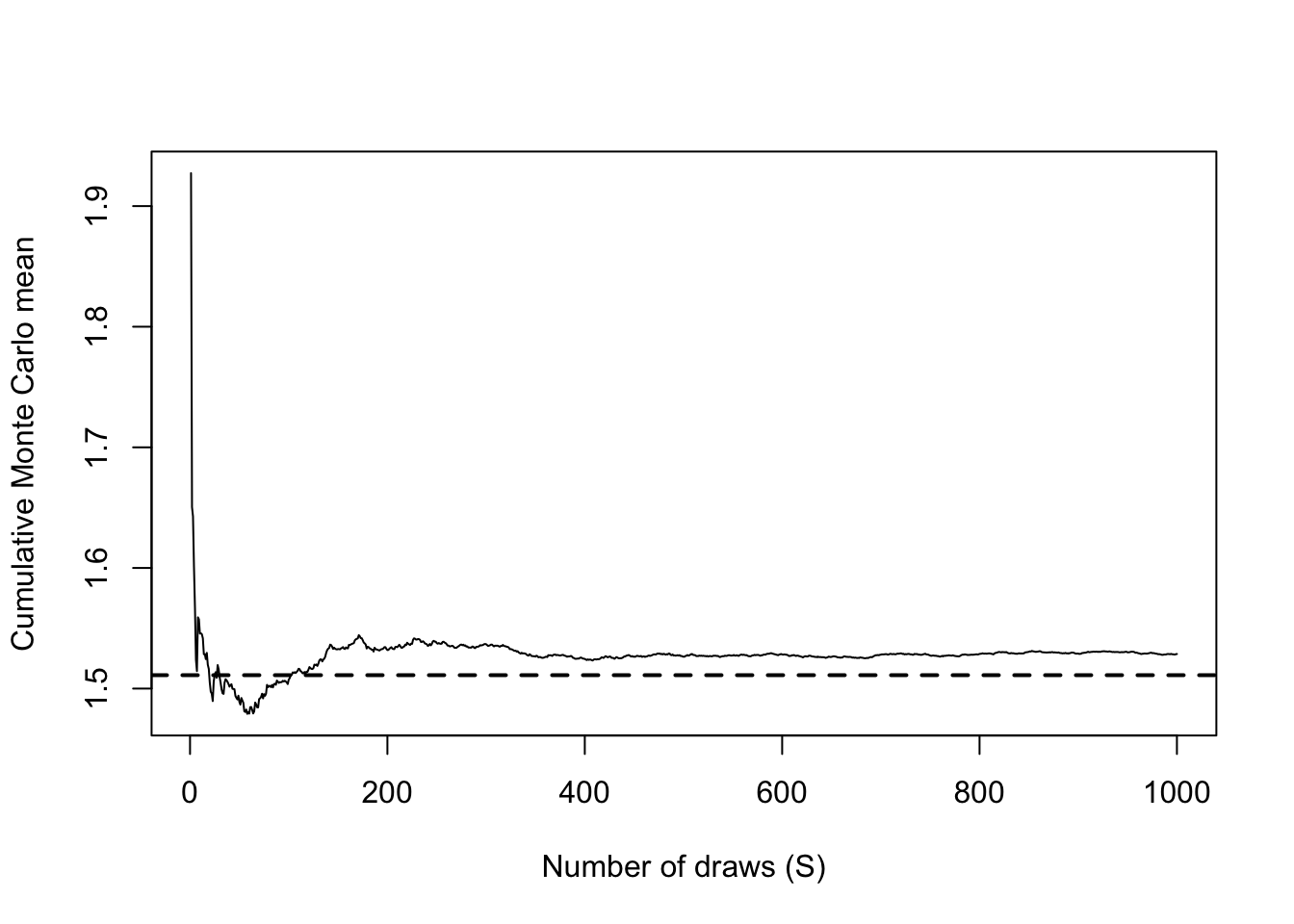
This is called a Monte Carlo approximation. By the Law of Large Numbers,
\[
\frac{1}{S}
\sum_{s=1}^S g(\theta^{(s)})
\;\longrightarrow\;
\mathbb{E}[g(\theta) \mid y] = \int g(\theta) p(\theta \mid y) d\theta
\quad \text{as } S \to \infty.
\] With the property above, we can calculate many quantities of interest about the posterior distribution. For example, suppose \(\bar{\theta}\) is the average of \(\{\theta^{(1)}, \dots, \theta^{(S)}\}\), then as \(S \to \infty\):
This avoids evaluating any double integrals. This is the foundation of modern Bayesian computation.
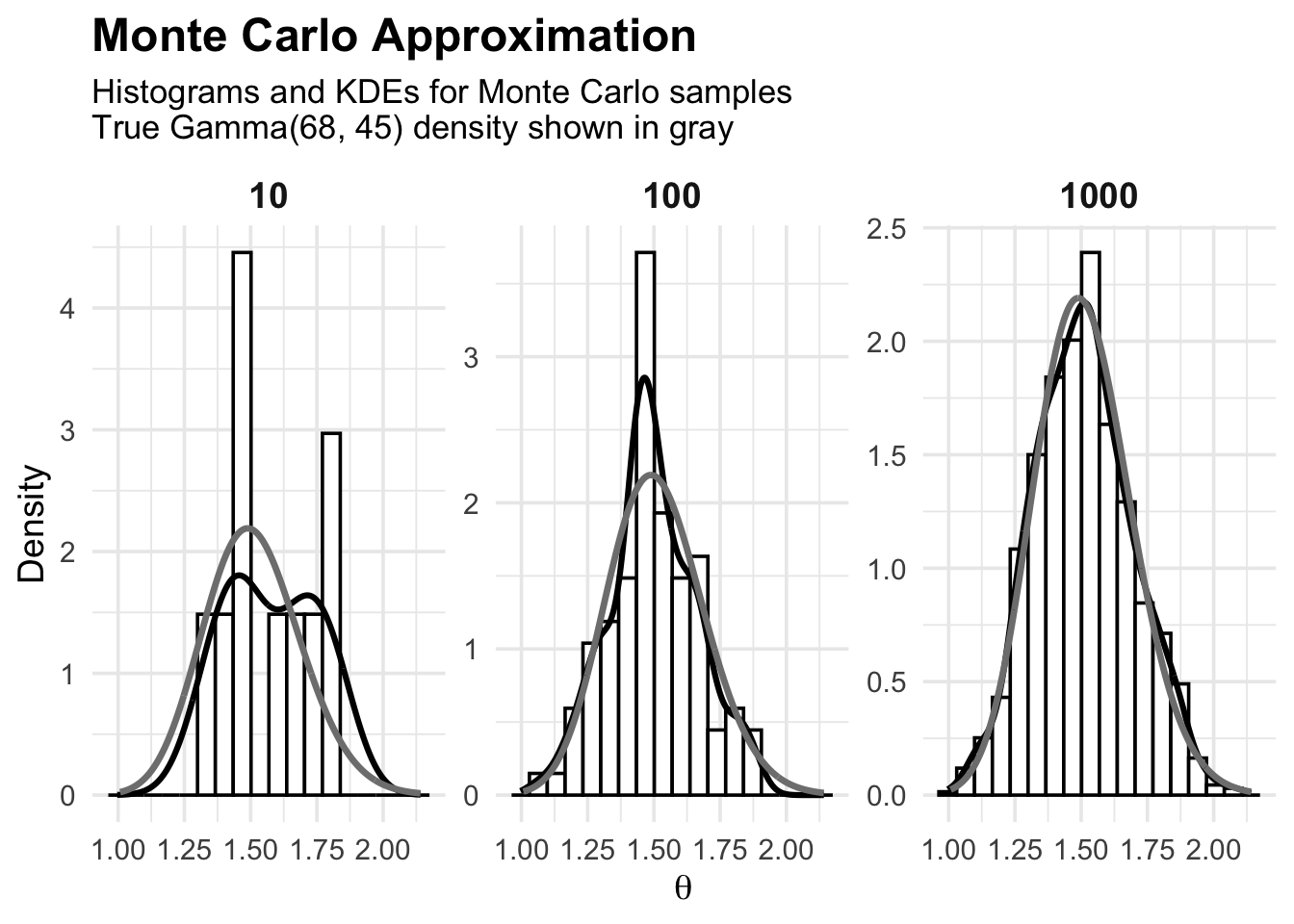
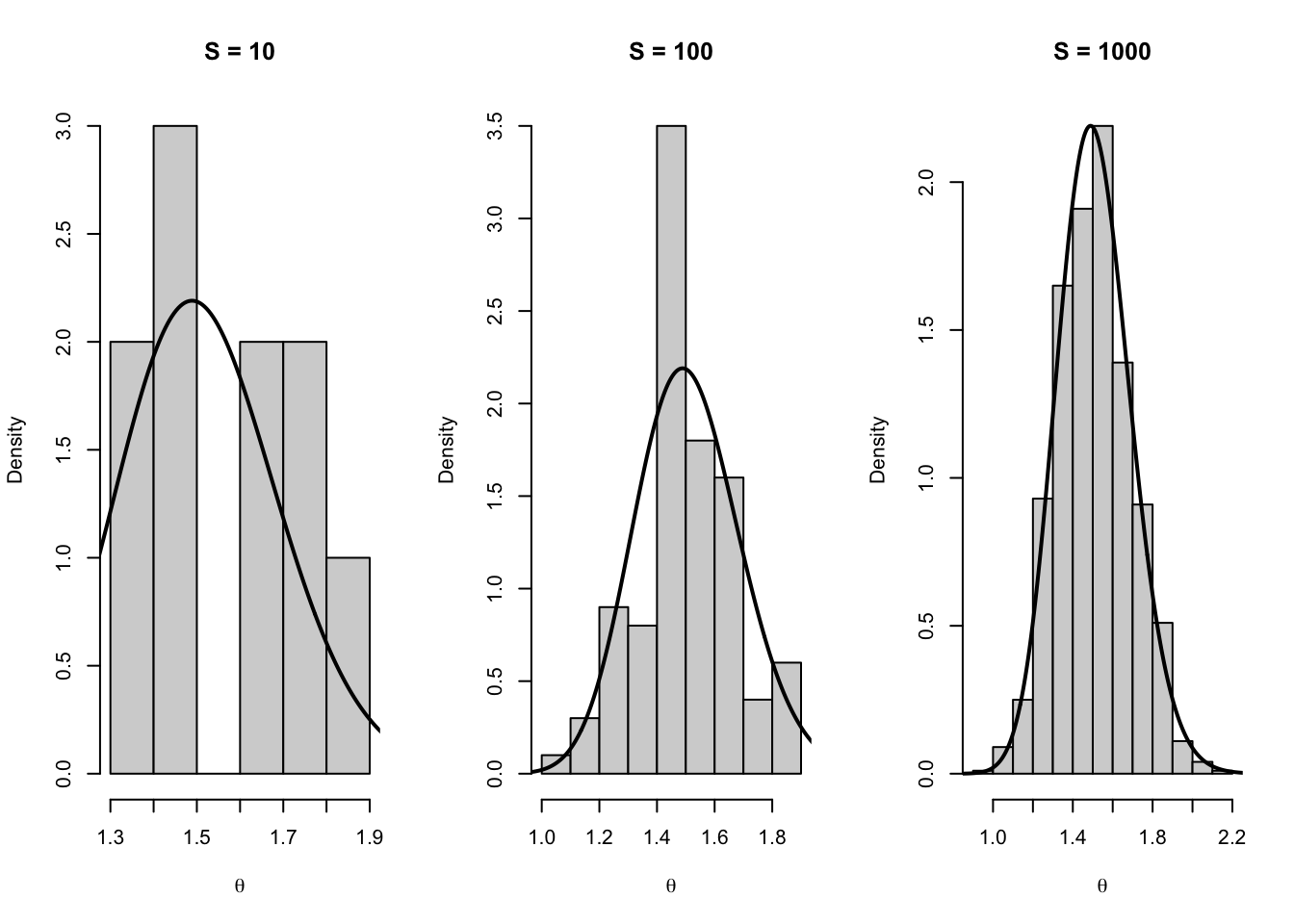
# Figure 4.1 — Monte Carlo Approximation (Gamma(68,45))# Histograms + KDEs for S = 10, 100, 1000; true density in grayset.seed(8310)library(ggplot2)# Posterior: Gamma(shape=68, rate=45)shape_post <-68rate_post <-45# MC samplesS_list <-c(10, 100, 1000)mc_df <-do.call(rbind, lapply(S_list, function(S) {data.frame(theta =rgamma(S, shape = shape_post, rate = rate_post),S =factor(S, levels = S_list))}))# Grid for true density (choose a sensible range around the mass)xgrid <-seq(qgamma(0.001, shape = shape_post, rate = rate_post),qgamma(0.999, shape = shape_post, rate = rate_post),length.out =600)true_df <-data.frame(theta = xgrid,dens =dgamma(xgrid, shape = shape_post, rate = rate_post))# Plotggplot(mc_df, aes(x = theta)) +# histogram (density scale so it overlays with densities)geom_histogram(aes(y =after_stat(density)),bins =18, color ="black", fill ="white") +# KDE from MC samplesgeom_density(linewidth =1.1) +# True density (gray)geom_line(data = true_df, aes(x = theta, y = dens),linewidth =1.2, color ="gray50") +facet_wrap(~ S, nrow =1, scales ="free_y") +labs(title ="Monte Carlo Approximation",subtitle =paste("Histograms and KDEs for Monte Carlo samples","True Gamma(68, 45) density shown in gray",sep ="\n" ),x =expression(theta),y ="Density" ) +theme_minimal(base_size =14) +theme(plot.title =element_text(size =18, face ="bold"),plot.subtitle =element_text(size =13),strip.text =element_text(size =14, face ="bold") )
4.2.1.1 Numerical Evaluation
We now compare MC approximations to quantities that can be computed analytically in this conjugate example.
4.2.2 MC for predictive distribution and Sampling from it
As discussed earlier, the predictive distribution of a future random variable \(\tilde Y\) is the probability distribution that reflects uncertainty about \(\tilde Y\) after accounting for both:
known quantities (conditioned on observed data), and
unknown quantities (integrated out).
4.2.2.1 Sampling Model vs Predictive Model
Suppose \(\tilde Y\) denotes the number of children for a randomly selected woman aged 40 with a college degree.
If the true mean birthrate \(\theta\) were known, uncertainty about \(\tilde Y\) would be described by the sampling model\[
\Pr(\tilde Y = \tilde y \mid \theta) = p(\tilde y \mid \theta)
= \frac{\theta^{\tilde y} e^{-\theta}}{\tilde y!},
\] that is, \[
\tilde Y \mid \theta \sim \text{Poisson}(\theta).
\]
In practice, however, \(\theta\) is unknown. Therefore, predictions must account for uncertainty in \(\theta\).
4.2.2.2 Prior Predictive Distribution
If no data have been observed, predictions are obtained by integrating out \(\theta\) using the prior distribution: \[
\Pr(\tilde Y = \tilde y)
= \int p(\tilde y \mid \theta)\, p(\theta)\, d\theta.
\]
This is called the prior predictive distribution.
For a Poisson model with a Gamma prior, \[
\theta \sim \text{Gamma}(a,b),
\] the prior predictive distribution of \(\tilde Y\) is \[
\tilde Y \sim \text{Negative Binomial}(a,b).
\]
4.2.2.3 Posterior Predictive Distribution
After observing data \(Y_1 = y_1, \ldots, Y_n = y_n\), the relevant predictive distribution for a new observation is \[
\Pr(\tilde Y = \tilde y \mid Y_1=y_1,\ldots,Y_n=y_n)
= \int p(\tilde y \mid \theta)\, p(\theta \mid y_1,\ldots,y_n)\, d\theta.
\]
This distribution is called the posterior predictive distribution.
For the Poisson–Gamma model, the posterior distribution is \[
\theta \mid y_1,\ldots,y_n \sim \text{Gamma}\!\left(a + \sum_{i=1}^n y_i,\; b+n\right),
\] and the posterior predictive distribution is again Negative Binomial.
4.2.2.4 MC Sampling from the Posterior Predictive Distribution
In many models, the posterior predictive distribution cannot be evaluated analytically. However, it can often be sampled using MC methods.
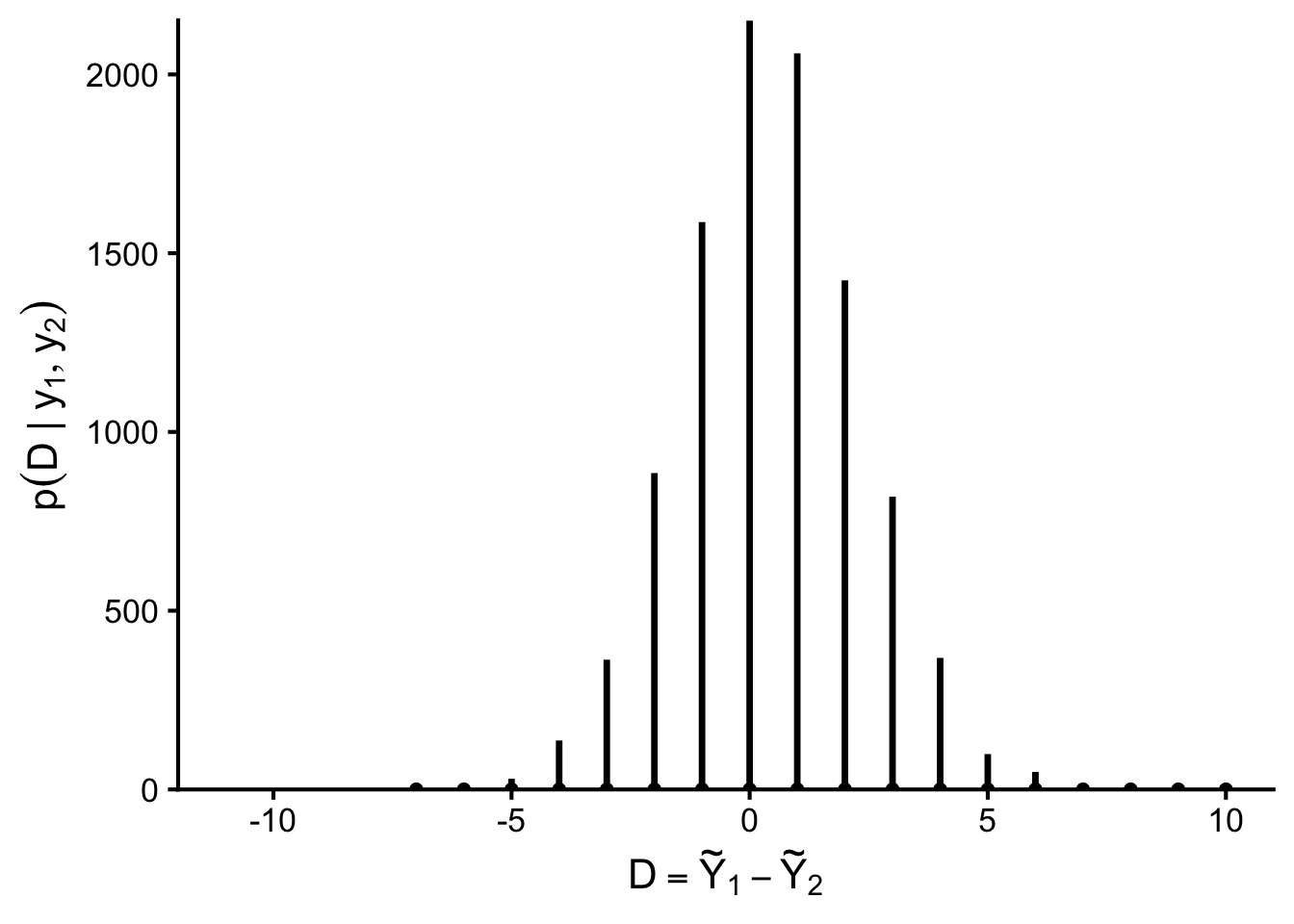
Using Monte Carlo samples \(\{\tilde Y_1^{(s)}, \tilde Y_2^{(s)}\}\), we can approximate quantities such as \[
\Pr(\tilde Y_1 > \tilde Y_2 \mid \text{data})
\approx
\frac{1}{S} \sum_{s=1}^S
\mathbb{I}\bigl(\tilde Y_1^{(s)} > \tilde Y_2^{(s)}\bigr).
\]
More generally, MC samples from the posterior predictive distribution allow us to approximate:
predictive probabilities,
predictive expectations,
quantiles and credible intervals,
functions of future observations.
This flexibility is one of the main strengths of MC methods in Bayesian analysis.
4.3 Posterior inference for arbitrary functions
Often we care about the posterior distribution of some computable function \(g(\theta)\) of a parameter \(\theta\). For example, in the binomial model we may be interested in the log-odds\[
\text{log odds}(\theta)
= \log\!\left(\frac{\theta}{1-\theta}\right)
= \gamma.
\]
If we can generate posterior draws \(\{\theta^{(1)},\theta^{(2)},\ldots\}\) from \(p(\theta\mid y_1,\ldots,y_n)\), then the law of large numbers implies that Monte Carlo averages converge to posterior expectations. For instance, \[
\frac{1}{S}\sum_{s=1}^S \log\!\left(\frac{\theta^{(s)}}{1-\theta^{(s)}}\right)
\;\longrightarrow\;
\mathbb{E}\!\left[\log\!\left(\frac{\theta}{1-\theta}\right)\middle|y_1,\ldots,y_n\right].
\]
More generally, we can approximate the entire posterior distribution of \[
\gamma = g(\theta) = \log\!\left(\frac{\theta}{1-\theta}\right)
\] by transforming posterior samples:
The collection \(\{\gamma^{(1)},\ldots,\gamma^{(S)}\}\) approximates the posterior distribution of \(\gamma\), so we can estimate posterior means, variances, quantiles, and credible intervals for \(\gamma\) directly from these transformed draws.
4.3.1 Posterior Predictive Model Checking
library(ggplot2)set.seed(8670)## --- Birth-rate example (Hoff): posterior predictive for D = Y~1 - Y~2 ---a <-2; b <-1n1 <-111; sy1 <-217# less than bachelor'sn2 <-44; sy2 <-66# bachelor's or highershape1 <- a + sy1; rate1 <- b + n1shape2 <- a + sy2; rate2 <- b + n2S <-10000# using 10,000 makes the y-axis peak around ~2000 (counts), like Fig 4.5theta1 <-rgamma(S, shape = shape1, rate = rate1)theta2 <-rgamma(S, shape = shape2, rate = rate2)y1 <-rpois(S, lambda = theta1)y2 <-rpois(S, lambda = theta2)D <- y1 - y2df <-as.data.frame(table(D))df$D <-as.integer(as.character(df$D))df$Freq <-as.numeric(df$Freq)xlim <-c(-12, 11)ggplot(df, aes(x = D, y = Freq)) +geom_segment(aes(xend = D, y =0, yend = Freq),linewidth =1.2, color ="black") +geom_point(aes(y =0), size =1.6, color ="black") +coord_cartesian(xlim = xlim, expand =FALSE) +labs(x =expression(D ==tilde(Y)[1] -tilde(Y)[2]),y =expression(p(D~"|"~y[1],y[2])) ) +theme_classic(base_size =16)
Posterior predictive model checking assesses whether a fitted Bayesian model can plausibly reproduce key features of the observed data. Back to the example we studied before, we focus on women aged 40 without a college degree. The empirical distribution of the number of children for these women, together with the corresponding posterior predictive distribution.
In this sample of size \(n = 111\), the number of women with exactly two children is \(y_{\text{obs}} = 38,\) which is twice the number of women with exactly one child.
In contrast, the posterior predictive distribution (shown in gray) suggests that sampling a woman with two children is slightly less likely than sampling a woman with one child, with probabilities approximately \[
0.27 \quad \text{vs.} \quad 0.28.
\]
These two distributions appear to be in conflict: if the observed data contain twice as many women with two children as with one child, why does the model predict otherwise?
Possible Explanations
One explanation is sampling variability. The empirical distribution of a finite sample does not necessarily match the true population distribution, and with moderate sample sizes, random fluctuations can be substantial. A smooth population distribution can easily produce a bumpy empirical histogram.
An alternative explanation is model misspecification. In particular, the Poisson model cannot capture certain features of the data. There is no Poisson distribution with a sharp peak at \(y = 2\), whereas the empirical distribution shows exactly such behaviour.
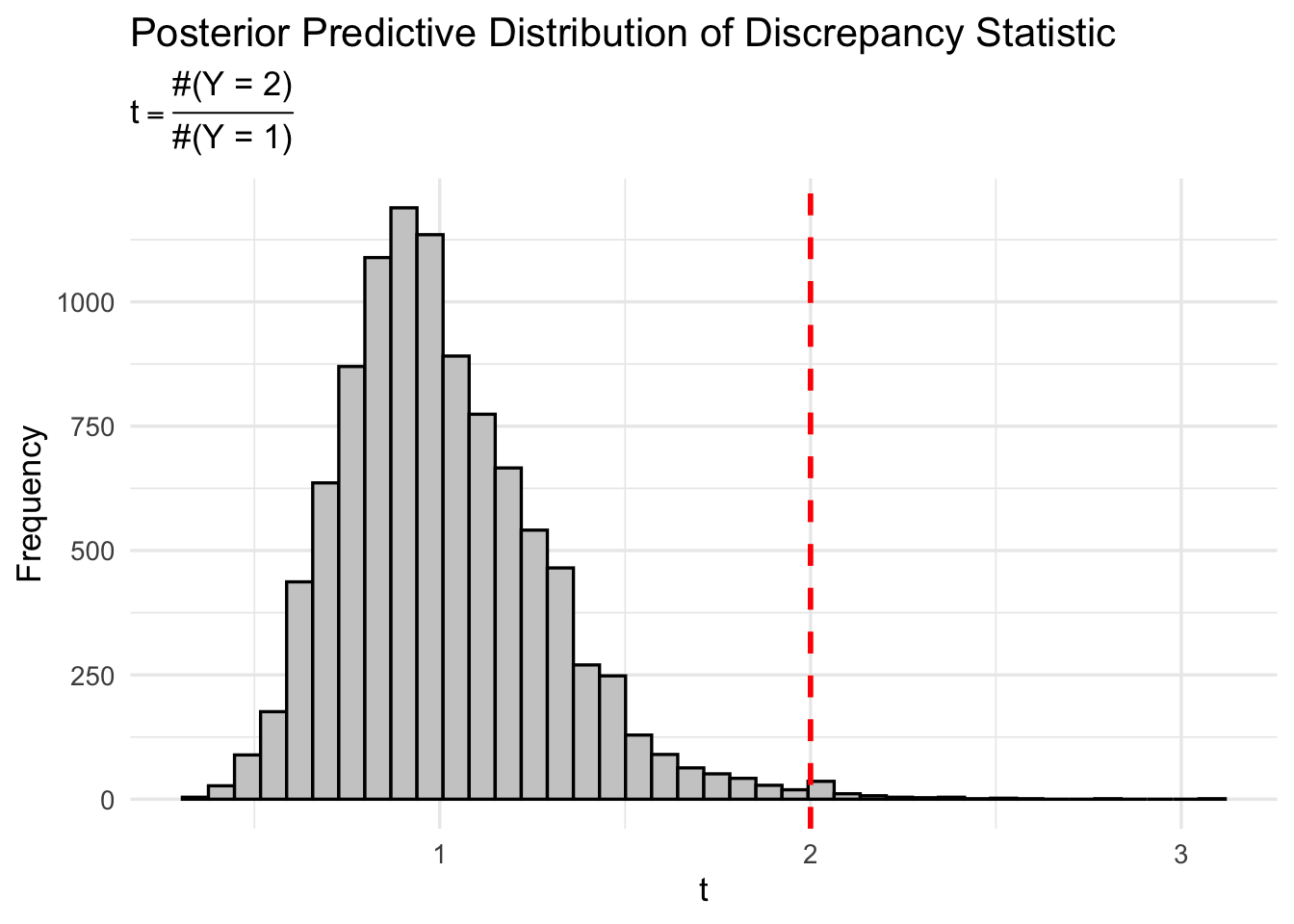
These explanations can be investigated systematically using Monte Carlo simulation. Define the discrepancy statistic\[
t(y) = \frac{\#{y_i = 2}}{\#{y_i = 1}},
\] the ratio of the number of women with two children to the number with one child.
For the observed data, \(t(y_{\text{obs}}) = 2.\) To assess whether this value is surprising under the model, we examine the posterior predictive distribution of \(t(\tilde{Y})\).
For each Monte Carlo iteration \(s = 1, \dots, S\):
Sample from the posterior \[\theta^{(s)} \sim p(\theta \mid y_{\text{obs}})\]
This Figure shows the posterior predictive distribution of \(t(\tilde{Y})\), with the observed value \(t(y_{\text{obs}})=2\) indicated by a vertical line. Out of 10,000 Monte Carlo samples, only about 0.71% produce values of \[
t(\tilde{Y}) \ge t(y_{\text{obs}}).
\]
This indicates that the observed discrepancy is extremely unlikely under the fitted Poisson model.
Conclusion
The posterior predictive check suggests that the Poisson model is inadequate for these data. Although it matches the posterior mean reasonably well, it fails to reproduce important distributional features.
This does not imply that the model is useless for all inferential goals. However, if our goal is to accurately describe the distribution of family sizes, a more flexible model is needed.
Posterior predictive checks provide a principled, simulation-based tool for diagnosing such failures and guiding model refinement.