6Week 5: Multiple Regression, Partial Effects, and Categorical Predictors
In this week, we move from simple regression ideas to multiple regression. We study how regression coefficients are interpreted when several predictors are included in the model, how categorical predictors enter through indicator variables, and how interactions change the meaning of coefficients. The main goal is to help students read, build, and interpret regression models in realistic settings.
6.1 Learning Objectives
By the end of this week, students should be able to:
interpret coefficients in a multiple regression model;
explain the meaning of a partial regression coefficient;
distinguish between marginal association and adjusted association;
incorporate categorical predictors using indicator variables;
interpret regression models with interactions;
use software output to explain fitted multiple regression models.
In earlier weeks, we focused on estimation, inference, ANOVA decomposition, and the comparison of nested models. In this week, the emphasis shifts toward interpretation and modelling structure.
This interpretation may or may not be scientifically meaningful.
Sometimes zero is a natural baseline. Sometimes it is outside the observed range, in which case the intercept is mainly a mathematical anchor for the model.
\(\beta_1\) is the expected change in \(Y\) associated with a one-unit increase in \(x_1\), holding \(x_2\) fixed;
\(\beta_2\) is the expected change in \(Y\) associated with a one-unit increase in \(x_2\), holding \(x_1\) fixed.
This is called a partial effect or adjusted effect.
The phrase “holding other variables fixed” is essential and should always be stated clearly.
6.8 Marginal Association Versus Adjusted Association
Suppose \(x_1\) and \(x_2\) are correlated.
Then the relationship between \(Y\) and \(x_1\) in a simple regression of \(Y\) on \(x_1\) alone may differ from the coefficient of \(x_1\) in a multiple regression including both \(x_1\) and \(x_2\).
This happens because:
the simple regression coefficient describes a marginal association;
the multiple regression coefficient describes an adjusted association.
These can differ substantially when predictors are related to each other.
6.9 Example of Adjusted Interpretation
Suppose we fit
\[
\widehat{Y} = 12.5 + 0.8\,x_1 - 1.2\,x_2.
\]
Then:
for each one-unit increase in \(x_1\), the fitted mean response increases by 0.8 units, holding \(x_2\) fixed;
for each one-unit increase in \(x_2\), the fitted mean response decreases by 1.2 units, holding \(x_1\) fixed.
This interpretation is valid only within the modelling assumptions and over the range of data where the model is reasonable.
6.10 Matrix View of Multiple Regression
In multiple regression, the design matrix has the form
So coefficients are interpreted relative to the reference category.
6.14 Why We Do Not Include All Indicators with an Intercept
If a categorical variable has \(k\) levels, then with an intercept we include only \(k-1\) indicator variables.
If we include all \(k\) indicators and also include an intercept, then the columns of the design matrix become linearly dependent. This causes rank deficiency.
This is sometimes called the dummy variable trap.
6.15 Continuous and Categorical Predictors Together
Regression models often mix continuous and categorical predictors.
The reduced model is nested within the full model by setting
\[
\beta_3 = 0.
\]
So the interaction can be tested by a standard extra sum of squares \(F\) test.
6.21 Collinearity and Interpretation
In multiple regression, predictors may be strongly related to each other.
When this happens:
coefficient estimates can become unstable;
standard errors can become large;
interpretation becomes more delicate.
Even when the overall model seems useful, individual coefficients may be hard to estimate precisely.
This issue is called multicollinearity.
We will study diagnostics for it more formally later, but students should already know that “holding other variables fixed” may become practically difficult if predictors tend to move together.
6.22 Multiple Regression as Conditional Mean Modelling
A good way to summarize multiple regression is:
\[
\mathbb{E}[Y \mid X_1,\dots,X_p]
\]
is being modelled as a linear function of predictors and model terms.
This viewpoint helps unify:
continuous predictors;
factors;
interactions;
transformed predictors.
It also helps students distinguish between the response itself and its conditional mean.
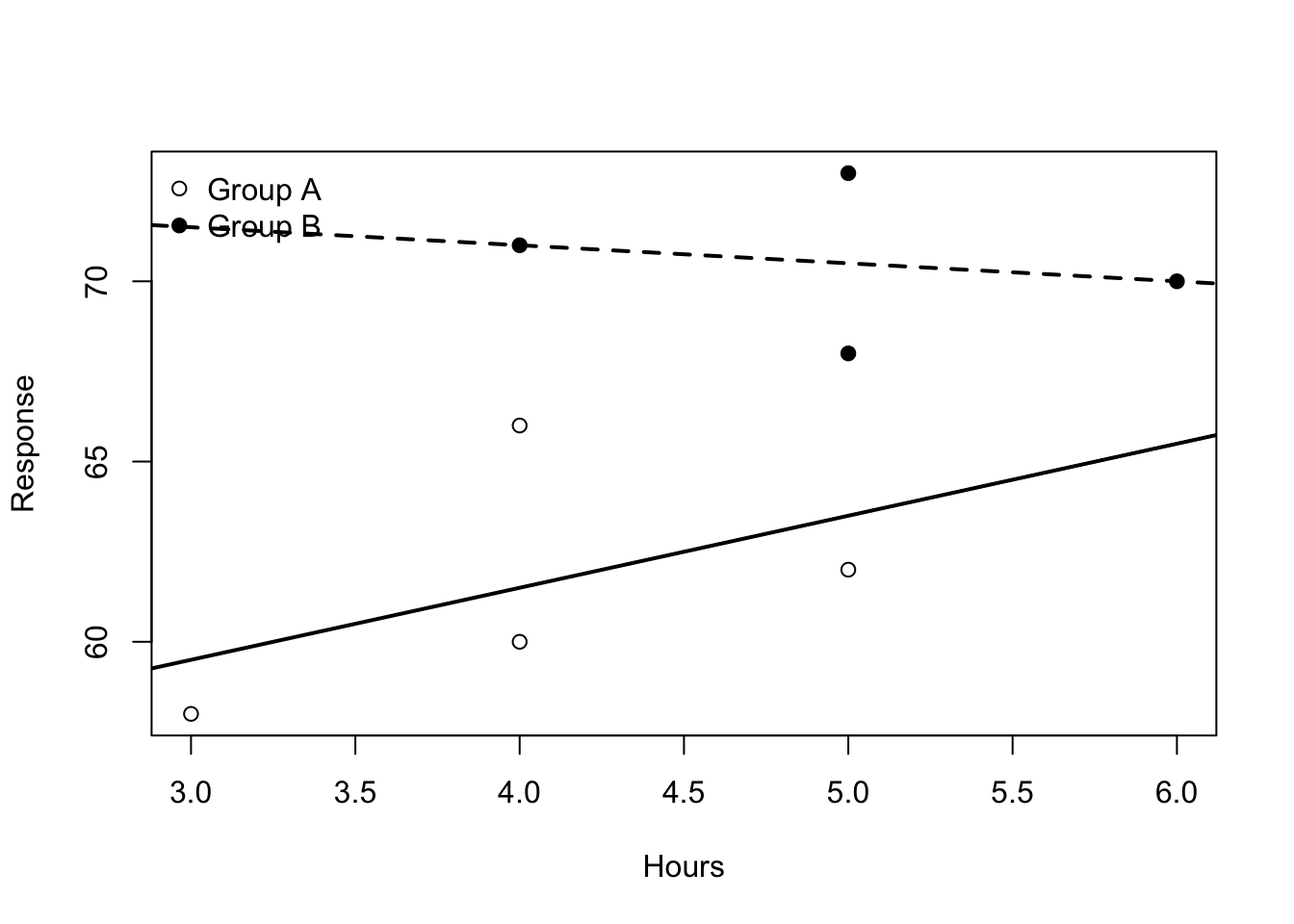
6.23 Worked Example With a Continuous and a Binary Predictor
Suppose we observe a response \(Y\), a study-hours variable \(x\), and a tutoring indicator \(z\), where
Analysis of Variance Table
Model 1: y ~ hours + group
Model 2: y ~ hours * group
Res.Df RSS Df Sum of Sq F Pr(>F)
1 5 45.75
2 4 39.50 1 6.25 0.6329 0.4708
In summary(lm(...)), each coefficient estimate answers a question about the conditional mean given the model terms included.
Students should always ask:
what variables are being held fixed;
what is the reference category;
whether an interaction changes the meaning of the main effects;
whether zero is a meaningful baseline for interpretation.
These questions matter more than memorizing formulas.
6.31 In-Class Discussion Questions
Why can the coefficient of a predictor change when a second predictor is added to the model?
Why do we need a reference category for categorical predictors?
How does an interaction change the interpretation of a main effect?
When might centring a predictor improve interpretation?
6.32 Practice Problems
6.33 Conceptual
Explain the meaning of a partial regression coefficient in your own words.
Explain the difference between a marginal association and an adjusted association.
Explain why a model with an interaction requires more careful interpretation than an additive model.
6.34 Computational
Suppose the fitted model is
\[
\hat{Y} = 10 + 2x_1 - 3x_2.
\]
Interpret the coefficient of \(x_1\).
Interpret the coefficient of \(x_2\).
Compute the fitted mean response when \(x_1 = 4\) and \(x_2 = 1\).
Now suppose the fitted model is
\[
\hat{Y} = 20 + 5x + 7z - 2xz,
\]
where \(z\) is binary.
Write the fitted mean function when \(z=0\).
Write the fitted mean function when \(z=1\).
Interpret the interaction coefficient.
6.35 Indicator Variable Problem
A factor has four levels: A, B, C, and D.
How many indicator variables are needed if the model includes an intercept?
If A is the reference group, write a regression model using indicators for B, C, and D.
State the expected response for each group.
6.36 Suggested Homework
Complete the following tasks:
fit a multiple regression model with at least two continuous predictors and interpret all coefficients;
fit a model with one continuous predictor and one categorical predictor, then identify the reference category and explain all coefficients;
add an interaction term and compare the additive and interaction models;
use model.matrix() in R to inspect the design matrix for a model with factors;
write a short explanation of why coefficient interpretation changes when additional predictors are added.
6.37 Summary
In this week, we developed the interpretation of multiple regression models.
We emphasized that:
regression coefficients in multiple regression are partial effects;
categorical predictors are incorporated through indicator variables;
interactions allow the effect of one predictor to depend on another;
the meaning of a coefficient depends on the full model specification.
These ideas are essential for moving from formal least squares theory to practical statistical modelling.
Next week, a natural continuation is to study multicollinearity, variable selection, and model building, or to move into diagnostics and residual analysis, depending on the course emphasis.