12Week 11: Generalized Least Squares, Correlated Errors, and Beyond Ordinary Least Squares
In this week, we study what happens when the error terms in a linear model are no longer independent with common variance. This leads to generalized least squares, a natural extension of ordinary least squares that accounts for nonidentity covariance structure. The goal is to help students understand how the linear model changes when observations are correlated or have unequal precision in a more general matrix form.
12.1 Learning Objectives
By the end of this week, students should be able to:
explain why ordinary least squares is not always appropriate when errors are correlated or heteroscedastic;
state the generalized linear model covariance assumption for the error vector in a linear model context;
derive the generalized least squares estimator;
explain how generalized least squares reduces to ordinary least squares and weighted least squares in special cases;
interpret the transformed-model view of generalized least squares;
recognize practical examples of correlated errors and structured covariance models.
12.2 Reading
Recommended reading for this week:
Seber and Lee:
sections on generalized least squares
correlated observations and covariance structure
extensions of least squares methods
Montgomery, Peck, and Vining:
sections on departures from ordinary linear model assumptions
weighted and generalized least squares ideas
practical modelling considerations for dependence and unequal variance
12.3 Why Ordinary Least Squares Can Fail
So far, much of the course has relied on the classical assumption
But many real datasets do not satisfy this assumption.
Examples include:
repeated observations on the same unit;
measurements taken over time;
clustered or grouped data;
observations with known unequal precision;
spatial or serial dependence.
In such cases, ordinary least squares may still be unbiased for the mean model under suitable assumptions, but it is no longer the most efficient linear estimator, and the usual standard error formulas become incorrect.
When \(\mathbf{V}\) is replaced by an estimate, the resulting estimator is often called feasible GLS.
12.17 Feasible Generalized Least Squares
The basic idea of feasible GLS is:
propose a covariance model for \(\mathbf{V}\);
estimate the unknown covariance parameters from the data;
plug the estimated covariance matrix into the GLS formula.
This is practical, but it introduces an extra modelling step and relies on the covariance model being approximately correct.
12.18 Examples of Covariance Structures
Several structured covariance matrices appear often in applications.
12.18.1 Unequal Variances Only
If observations are independent but have different variances, then \(\mathbf{V}\) is diagonal.
This is the weighted least squares case.
12.18.2 Compound Symmetry
In grouped or repeated-measures settings, one may assume a common variance and a common correlation within group.
This gives a covariance pattern often called compound symmetry.
12.18.3 Autoregressive Structure
For time-ordered observations, nearby errors may be more strongly correlated than distant ones.
A simple model is the AR(1) structure, where correlations decay geometrically with lag.
12.18.4 Block-Diagonal Structure
If observations are grouped into independent clusters, then \(\mathbf{V}\) may be block diagonal, with each block describing within-cluster dependence.
These examples help students see that covariance structure is part of model formulation, not just a technical afterthought.
then ordinary least squares may still estimate the mean trend, but standard errors based on independence are not trustworthy.
This is one of the classic motivations for generalized least squares.
12.20 Clustered and Repeated Observations
Suppose several observations come from the same individual, school, hospital, or geographic region.
Then responses within the same cluster may be correlated.
In this case, the assumption of independent errors is not appropriate, and a structured covariance model or a mixed-model approach may be better suited.
GLS provides an important stepping stone toward these more advanced frameworks.
12.21 Relationship to Robust Standard Errors
One alternative to full covariance modelling is to keep the OLS mean estimator but adjust the standard errors to be robust to heteroscedasticity or dependence.
This is a different strategy from GLS.
GLS changes the estimator itself using a covariance model;
robust standard errors keep the estimator but correct inference approximately.
Both are useful, but they serve different purposes.
This distinction is valuable for students to understand even if robust methods are treated only briefly.
12.22 When GLS Is Worth Using
GLS is especially attractive when:
there is a defensible covariance model;
the dependence or heteroscedasticity is substantial;
efficient estimation matters;
the transformed model remains interpretable.
If the covariance model is poorly specified, the gains from GLS may be limited, and robustness or alternative modelling strategies may be preferable.
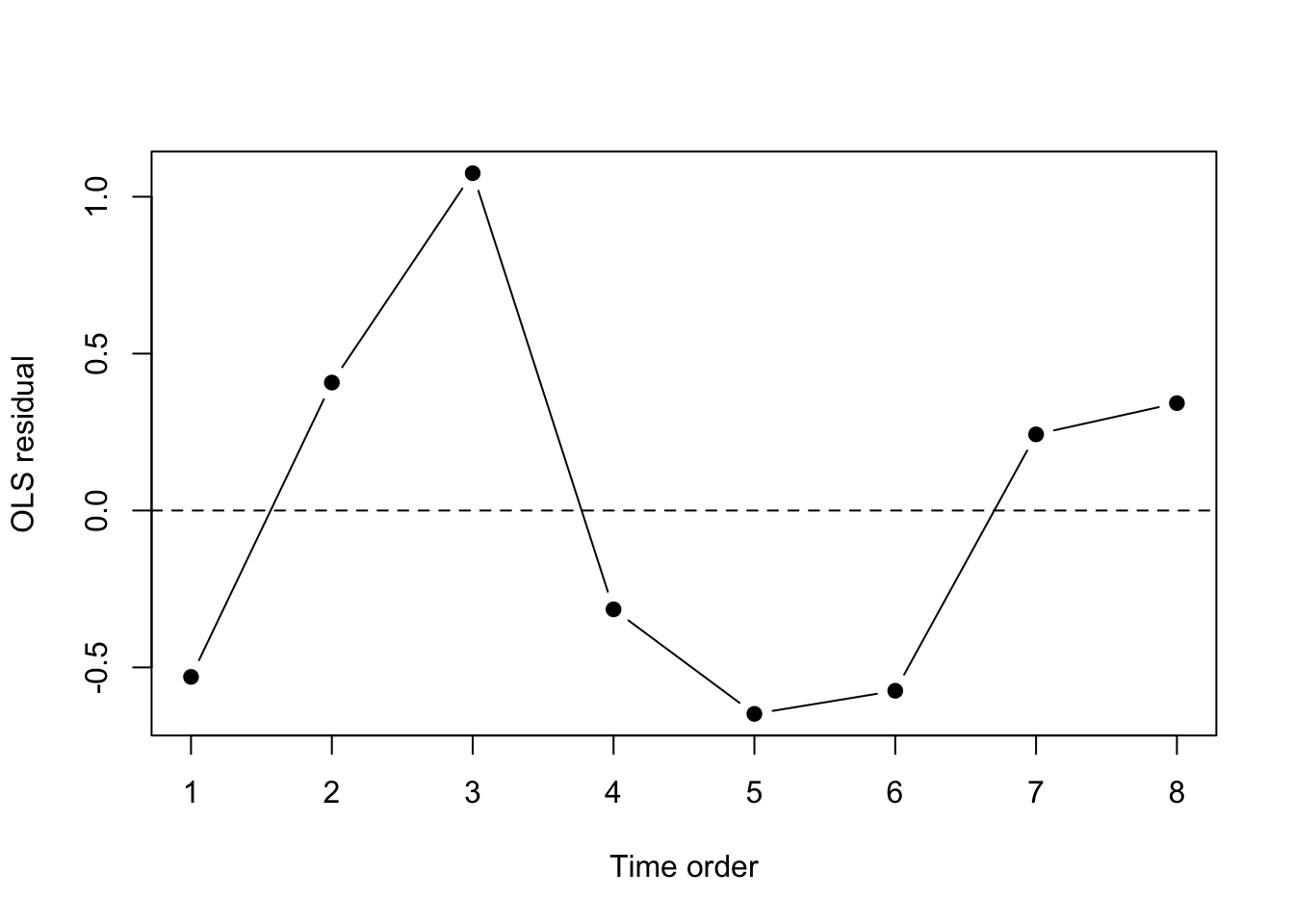
12.23 Diagnostics for Correlated Errors
Symptoms that may suggest correlated errors include:
residuals that display runs or systematic temporal patterns;
residual plots against time showing clustering;
repeated-measures structure built into the design;
known grouping or spatial dependence in the data collection process.
The key lesson is that covariance structure should be motivated both by diagnostics and by how the data were collected.
12.24 Worked Example With Known Unequal Precision
Suppose each response is an average of \(m_i\) repeated measurements.
Then the variance of the average may satisfy
\[
\mathrm{Var}(Y_i) = \frac{\sigma^2}{m_i}.
\]
In that case, a natural choice is
\[
v_i = \frac{1}{m_i},
\qquad
w_i = m_i.
\]
So observations based on more repeated measurements get more weight.
This is a very intuitive example of GLS through weighted least squares.
12.25 Worked Example With Correlated Pairs
Suppose observations come in natural pairs, and within each pair the errors are positively correlated.
Then the covariance matrix has a block structure, with a \(2\times2\) covariance block for each pair.
GLS accounts for the fact that the two observations in a pair do not contribute as much independent information as two unrelated observations would.
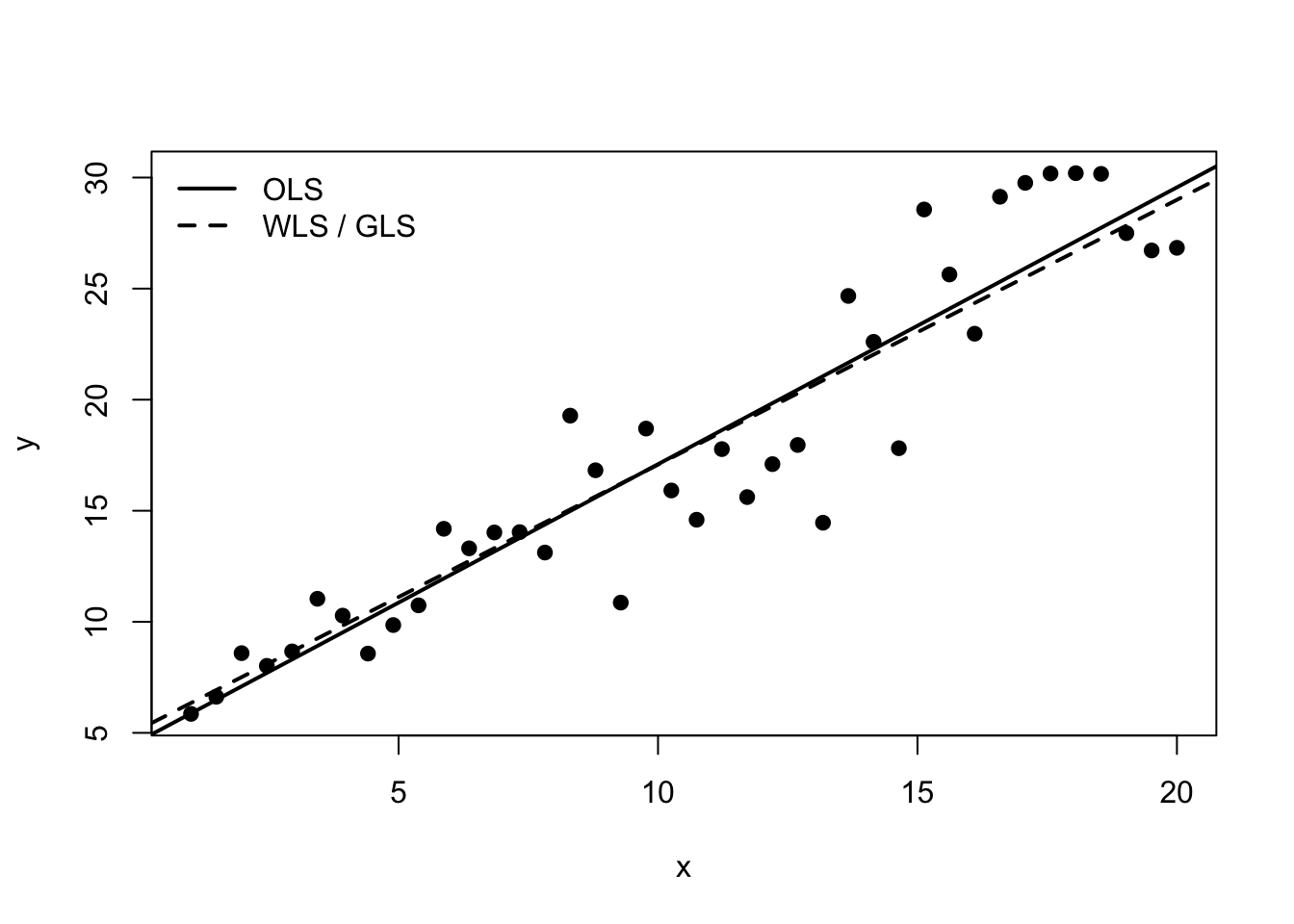
12.26 R Demonstration With Weighted Least Squares as GLS
12.27 Simulate data with unequal variances
set.seed(123)n <-40x <-seq(1, 20, length.out = n)v <-0.3+0.08* x^2y <-5+1.2* x +rnorm(n, sd =sqrt(v))dat <-data.frame(y = y, x = x, v = v)fit_ols <-lm(y ~ x, data = dat)fit_wls <-lm(y ~ x, data = dat, weights =1/ v)summary(fit_ols)
Call:
lm(formula = y ~ x, data = dat)
Residuals:
Min 1Q Median 3Q Max
-6.5979 -1.6024 0.2916 1.9490 5.0754
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 4.63093 0.93057 4.976 1.43e-05 ***
x 1.24643 0.07813 15.954 < 2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 2.779 on 38 degrees of freedom
Multiple R-squared: 0.8701, Adjusted R-squared: 0.8667
F-statistic: 254.5 on 1 and 38 DF, p-value: < 2.2e-16
summary(fit_wls)
Call:
lm(formula = y ~ x, data = dat, weights = 1/v)
Weighted Residuals:
Min 1Q Median 3Q Max
-1.9970 -0.6075 -0.0324 0.6769 1.7500
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 5.15391 0.34558 14.91 <2e-16 ***
x 1.19219 0.06256 19.05 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.9073 on 38 degrees of freedom
Multiple R-squared: 0.9053, Adjusted R-squared: 0.9028
F-statistic: 363.1 on 1 and 38 DF, p-value: < 2.2e-16
12.33 Simple example of grouped covariance intuition
set.seed(789)group <-rep(1:10, each =3)x3 <-rnorm(length(group))u <-rnorm(10, sd =1.2)eps3 <-rep(u, each =3) +rnorm(length(group), sd =0.5)y3 <-4+2* x3 + eps3dat3 <-data.frame(y = y3, x = x3, group =factor(group))fit3 <-lm(y ~ x, data = dat3)summary(fit3)
Call:
lm(formula = y ~ x, data = dat3)
Residuals:
Min 1Q Median 3Q Max
-1.3891 -0.6203 -0.2549 0.8272 1.4704
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 3.7259 0.1740 21.417 < 2e-16 ***
x 2.1131 0.2316 9.125 6.97e-10 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.8837 on 28 degrees of freedom
Multiple R-squared: 0.7484, Adjusted R-squared: 0.7394
F-statistic: 83.27 on 1 and 28 DF, p-value: 6.974e-10
12.34 Interpreting Software Output
In base R, ordinary lm() directly handles OLS and weighted least squares through the weights= argument.
More general correlated-error models often require additional packages in practice, but the matrix formula is already enough to understand the core idea of GLS.
Students should focus on:
what covariance structure is being assumed;
why that structure is plausible;
how the weighting or transformation changes the estimator;
what practical goal is being improved.
12.35 A Practical Workflow for GLS Thinking
A sensible workflow is:
ask whether independence and equal variance are plausible from the design of the study;
inspect residual patterns for signs of heteroscedasticity or dependence;
propose a covariance structure or weighting scheme when justified;
compare OLS and GLS-style fits;
interpret the results in light of both efficiency and model credibility.
12.36 In-Class Discussion Questions
Why is weighted least squares a special case of generalized least squares?
Why can correlated observations carry less information than independent observations?
What is the conceptual benefit of the transformed-model view of GLS?
When might robust standard errors be preferred to specifying a full covariance model?
12.37 Practice Problems
12.38 Conceptual
Explain why OLS is not generally efficient when the covariance matrix is not proportional to the identity.
Explain how GLS uses the inverse covariance matrix to weight information in the data.
Explain the difference between modelling the covariance structure and simply correcting standard errors.