7Week 6: Residual Analysis, Diagnostics, and Model Adequacy
In this week, we study how to assess whether a fitted linear regression model is adequate. After learning estimation, inference, ANOVA, and interpretation, we now turn to model checking. The main tools are residuals, diagnostic plots, and numerical measures that help identify nonlinearity, unequal variance, outliers, and influential observations.
7.1 Learning Objectives
By the end of this week, students should be able to:
explain why model diagnostics are necessary after fitting a regression model;
define raw, standardized, and studentized residuals;
interpret residual plots for common types of model failure;
distinguish between outliers in the response direction and influential observations in the design space;
use leverage, Cook’s distance, and related diagnostics;
assess model adequacy using graphical and numerical tools.
7.2 Reading
Recommended reading for this week:
Seber and Lee:
sections on residual analysis
diagnostics for regression models
influence and unusual observations
Montgomery, Peck, and Vining:
sections on residuals
diagnostic plots
outliers, leverage, and influence
7.3 Why Diagnostics Matter
A fitted regression model may look statistically significant and still be inappropriate.
For example:
the relationship may not be linear;
the error variance may not be constant;
the error distribution may be strongly non-normal;
a small number of unusual observations may dominate the fit.
So regression analysis does not end when we obtain estimates and \(p\)-values. We must also ask whether the model assumptions are reasonable and whether the fit is being driven by problematic observations.
This puts residuals on a comparable scale across observations.
Large absolute values of \(r_i\) may indicate unusual observations in the response direction.
7.10 Studentized Residuals
A more refined version is the studentized residual.
One version uses the variance estimate computed from the full model. Another version uses the variance estimate obtained after deleting the \(i\)th observation.
The externally studentized residual is often written as
Large values of \(D_i\) indicate potentially influential observations.
Plots of Cook’s distance help identify observations that deserve closer inspection.
7.22 DFFITS and DFBETAS
Other influence measures include:
DFFITS, which measures the effect of deleting an observation on its fitted value;
DFBETAS, which measure the effect of deleting an observation on each estimated coefficient.
These are useful when we want to know not only whether a point is influential, but how it changes the model.
For an introductory treatment, Cook’s distance and leverage usually provide a strong starting point.
7.23 Added-Variable and Partial Residual Plots
When there are several predictors, ordinary residual plots may not fully reveal whether one variable needs a nonlinear term or whether its effect remains after adjustment.
Useful advanced plots include:
added-variable plots, which assess the contribution of one predictor after adjusting for others;
partial residual plots, which help visualize possible nonlinearity for a specific predictor.
These are especially useful in multiple regression, though they are often introduced after students become comfortable with basic residual plots.
7.24 Diagnosing Nonlinearity
If the mean function is nonlinear but we fit a linear model, residual plots may show curvature.
Possible remedies include:
adding polynomial terms;
applying transformations;
including interactions;
using a different modelling framework.
Diagnostics should not be viewed only as fault-finding. They also guide model improvement.
7.25 Diagnosing Heteroscedasticity
If the error variance is not constant, residual plots may show a funnel shape or other changing spread.
Possible remedies include:
transforming the response;
weighted least squares;
modelling the variance structure explicitly;
using heteroscedasticity-robust standard errors in some contexts.
At this stage, the main goal is to recognize the pattern and understand its consequences.
7.26 Diagnosing Non-Normality
If residuals are strongly non-normal, this may affect exact small-sample inference.
Possible causes include:
skewed responses;
heavy-tailed errors;
outliers;
omitted structure.
Possible remedies include:
transformation;
alternative modelling assumptions;
robust procedures;
careful interpretation if sample size is large and inference is approximately stable.
7.27 Diagnostics Are Contextual
There is no single diagnostic that automatically declares a model valid or invalid.
Instead, diagnostics require judgment.
Students should ask:
Is the pattern strong or mild?
Is it scientifically meaningful?
Does one point dominate the fit?
Would conclusions change if the model were modified?
Is the issue important for the goal of the analysis: explanation, prediction, or inference?
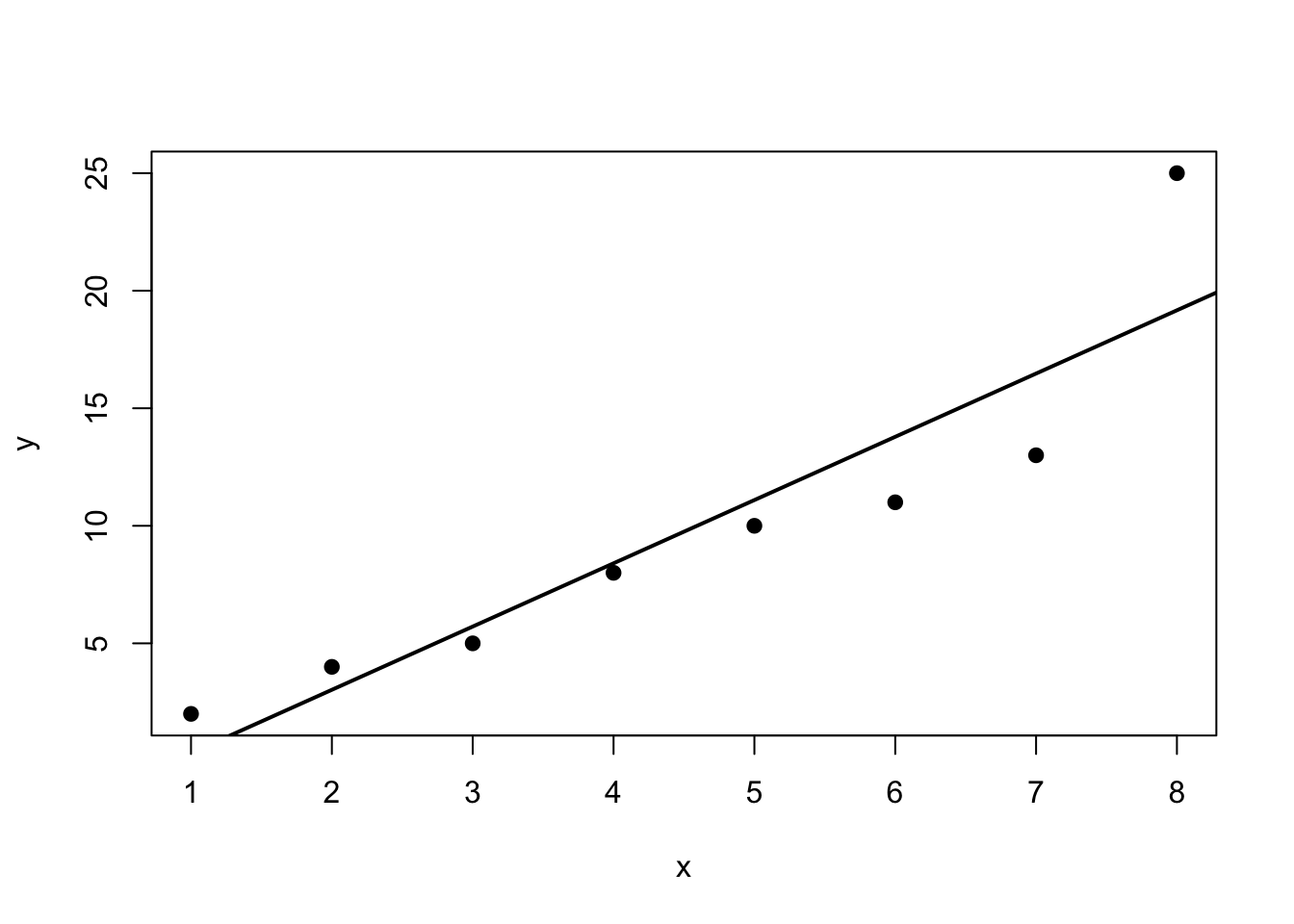
7.28 Worked Example With an Outlying Observation
Consider the data
\[
x = (1,2,3,4,5,6,7,8),
\]
and
\[
y = (2,4,5,8,10,11,13,25).
\]
The final observation may look unusual because the response jumps upward relative to the earlier trend.
If we fit a simple linear regression, we should examine:
the scatterplot with fitted line;
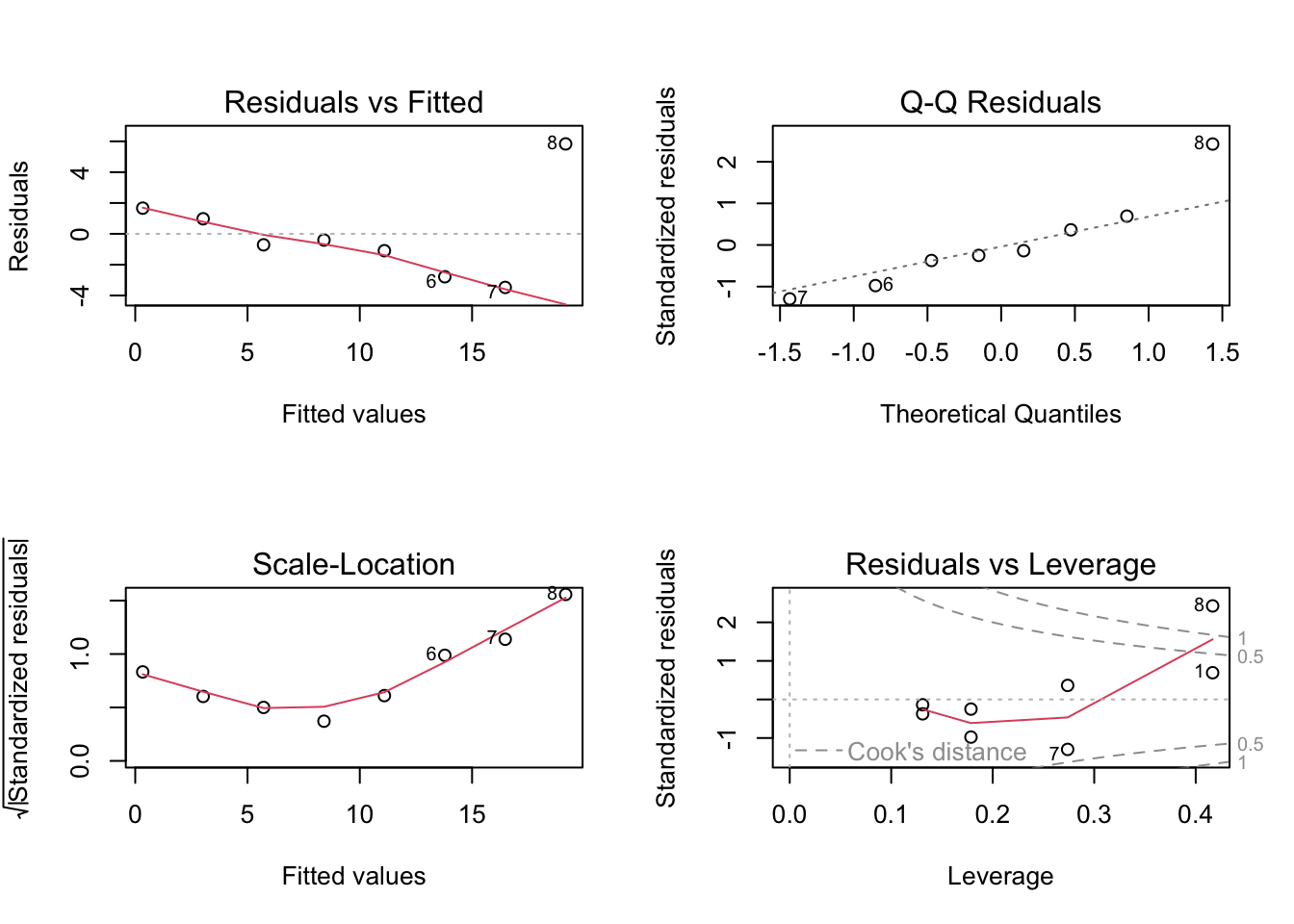
residuals versus fitted values;
studentized residuals;
leverage;
Cook’s distance.
This is a good example for discussing the difference between an outlier and an influential point.
7.29 R Demonstration With Basic Diagnostic Plots
7.30 Fit a simple model
x <-1:8y <-c(2, 4, 5, 8, 10, 11, 13, 25)dat <-data.frame(x = x, y = y)fit <-lm(y ~ x, data = dat)summary(fit)
Call:
lm(formula = y ~ x, data = dat)
Residuals:
Min 1Q Median 3Q Max
-3.4762 -1.5179 -0.5595 1.1488 5.8333
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -2.3571 2.4532 -0.961 0.37374
x 2.6905 0.4858 5.538 0.00146 **
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 3.148 on 6 degrees of freedom
Multiple R-squared: 0.8364, Adjusted R-squared: 0.8091
F-statistic: 30.67 on 1 and 6 DF, p-value: 0.001462
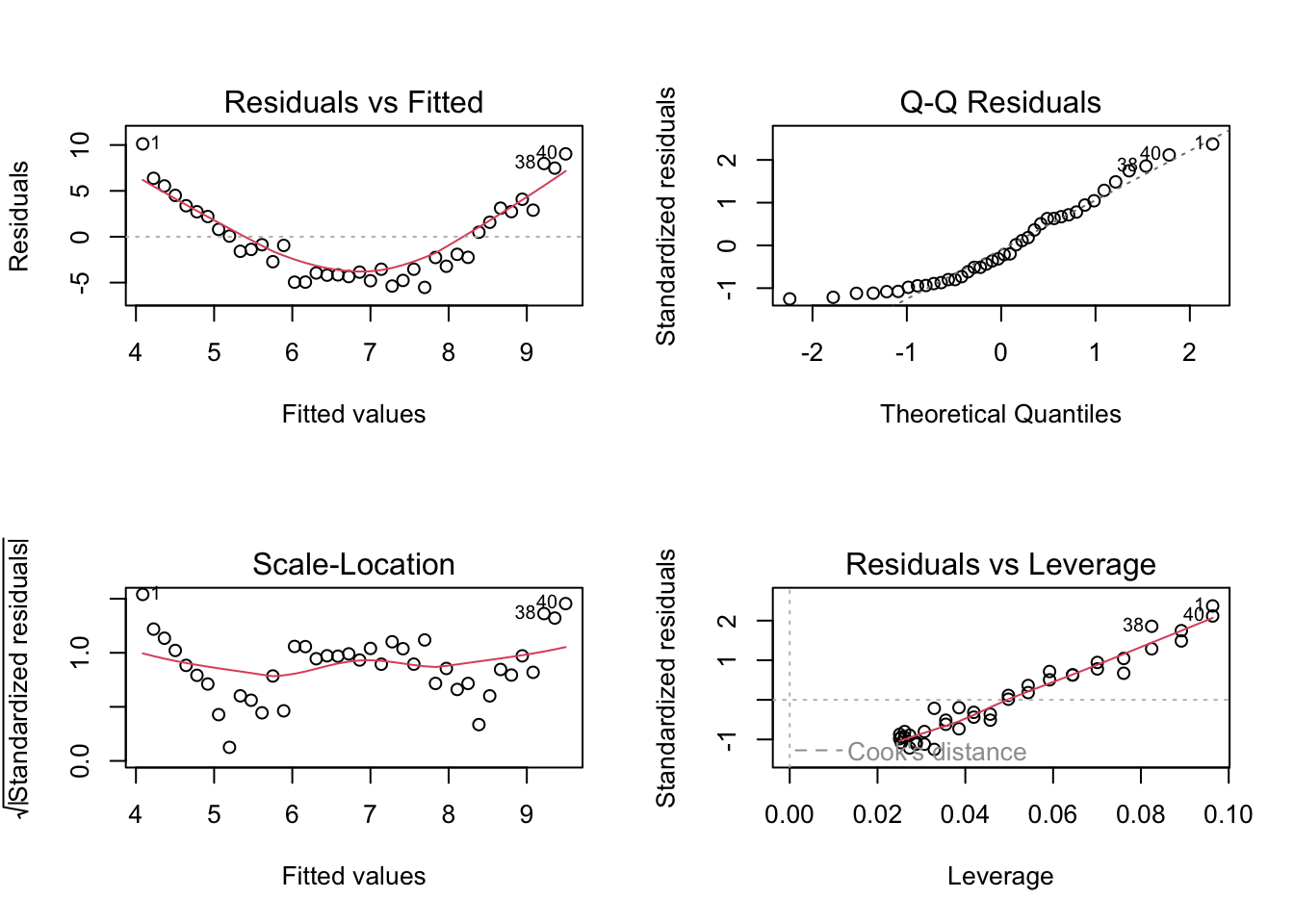
fit3_quad <-lm(y ~ x +I(x^2), data = dat3)anova(fit3, fit3_quad)
Analysis of Variance Table
Model 1: y ~ x
Model 2: y ~ x + I(x^2)
Res.Df RSS Df Sum of Sq F Pr(>F)
1 38 765.56
2 37 37.17 1 728.39 725.14 < 2.2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
summary(fit3_quad)
Call:
lm(formula = y ~ x + I(x^2), data = dat3)
Residuals:
Min 1Q Median 3Q Max
-2.26296 -0.67453 0.07213 0.50424 2.31450
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 2.01622 0.23783 8.478 3.38e-10 ***
x 0.90164 0.08923 10.104 3.45e-12 ***
I(x^2) 1.51417 0.05623 26.928 < 2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 1.002 on 37 degrees of freedom
Multiple R-squared: 0.9572, Adjusted R-squared: 0.9549
F-statistic: 413.6 on 2 and 37 DF, p-value: < 2.2e-16
7.38 Interpreting Software Output
In practice, useful commands in R include:
plot(fit) for the standard diagnostic panel;
resid(fit) for residuals;
rstandard(fit) for standardized residuals;
rstudent(fit) for studentized residuals;
hatvalues(fit) for leverages;
cooks.distance(fit) for Cook’s distances.
Students should learn to connect each numerical output to a concrete modelling question.
7.39 A Practical Diagnostic Workflow
A sensible basic workflow is:
inspect the scatterplot and fitted line;
examine the residuals-versus-fitted plot;
check the normal Q-Q plot;
inspect leverage and Cook’s distance;
investigate any unusual observations directly in the data;
decide whether model revision is needed.
This sequence often works well for both simple and multiple regression.
7.40 What To Do After Finding a Problem
Finding a diagnostic issue does not mean we automatically delete observations.
Instead, possible next steps include:
checking for data entry or measurement errors;
understanding whether the point represents a different regime;
refitting with and without the point for sensitivity analysis;
revising the model form;
transforming variables;
reporting the issue transparently.
Model criticism should be thoughtful, not mechanical.
7.41 In-Class Discussion Questions
Why are raw residuals not enough for identifying unusual observations?
Why can a high-leverage point have a small residual and still matter?
Why is Cook’s distance more about influence than outlyingness?
What kinds of model failure are easiest to detect from a residual-versus-fitted plot?
7.42 Practice Problems
7.43 Conceptual
Explain the difference between an outlier, a high-leverage observation, and an influential observation.
Explain why residuals have unequal variance.
Explain why a normal Q-Q plot is useful even though residuals are not independent.
7.44 Computational
Suppose a regression model has \(n=25\) observations and \(p=4\) parameters.
Compute the rough leverage benchmark \(2p/n\).
If one observation has \(h_{ii}=0.45\), explain whether this seems unusually large.
Suppose an observation has a large studentized residual but very small leverage. What kind of problem does this suggest?
Suppose another observation has large leverage but a very small residual. Why might it still deserve attention?
7.45 Model-Criticism Problem
A residual-versus-fitted plot shows a clear U-shape.
What model assumption is likely failing?
What changes to the model might you consider?
Why would simply reporting coefficient \(p\)-values be insufficient here?
7.46 Suggested Homework
Complete the following tasks:
fit a regression model in R and produce the standard diagnostic plots;
identify any observations with large studentized residuals, high leverage, or large Cook’s distance;
write a short interpretation of each diagnostic plot;
modify a model to address one detected issue, such as curvature or unequal variance;
compare the original and revised models.
7.47 Summary
In this week, we studied model diagnostics for linear regression.
We focused on:
residuals and standardized residuals;
fitted-versus-residual plots;
normal Q-Q plots;
leverage and influence;
Cook’s distance and related ideas;
practical judgment in assessing model adequacy.
These ideas are essential because regression analysis is not complete until the fitted model has been critically examined.
Next week, a natural continuation is to study transformations, remedies for nonconstant variance, and weighted least squares, or to move into multicollinearity and model selection, depending on the course emphasis.