8Bayesian methods in Machine Learning: Regularization, Prediction, and Uncertainty
In this lecture, we explore several ways in which Bayesian statistics connects naturally with machine learning. The main message is that many ideas in modern machine learning have very natural Bayesian interpretations.
In particular, we will focus on three themes:
regularization as prior modelling,
prediction with uncertainty,
Bayesian thinking in modern machine learning.
8.1 Why connect Bayesian statistics and machine learning?
Many machine learning methods are designed to do one or more of the following:
estimate complicated models,
make predictions,
avoid overfitting,
quantify uncertainty.
Bayesian methods are also designed to address these goals, but from a probabilistic perspective.
A Bayesian analysis starts with a model for the data, specifies prior distributions on unknown parameters, and then uses the posterior distribution to update beliefs and make predictions.
Note
A useful way to think about the connection is:
machine learning often emphasizes prediction and optimization;
Bayesian statistics emphasizes probability models and uncertainty quantification.
In many cases, the two perspectives are closely related.
8.2 Roadmap
In this lecture we will study:
Bayesian linear regression as a probabilistic prediction model,
regularization as prior modeling,
posterior predictive uncertainty,
why these ideas matter in modern machine learning.
8.3 Bayesian linear regression as probabilistic machine learning
So instead of a single estimate, we get a full distribution over plausible values of the regression coefficients.
Note
This is one of the key Bayesian ideas in machine learning:
Instead of learning one parameter value, we learn a distribution over parameter values.
8.3.2 Why is this useful?
A posterior distribution over \(\boldsymbol{\beta}\) gives us:
point estimates such as posterior means,
interval estimates such as credible intervals,
predictive distributions for new observations,
uncertainty quantification.
This is especially useful when:
sample sizes are small,
predictors are correlated,
overfitting is a concern,
prediction uncertainty matters.
8.4 Regularization as prior modeling
One of the most important connections between Bayesian statistics and machine learning is that regularization can often be interpreted as a prior distribution.
8.4.1 Why regularization?
In machine learning, flexible models can easily overfit the data. To control complexity, we often add a penalty term.
Maximizing the posterior is therefore equivalent to minimizing a penalized least squares criterion. In particular, the Gaussian prior corresponds to an \(L_2\) penalty.
Important
A Gaussian prior on coefficients corresponds to ridge-type shrinkage.
So a prior is not only a statement about beliefs. It is also a way to control model complexity.
This is a powerful connection, because it shows that many machine learning penalties can be understood as prior distributions.
8.4.4 Why shrinkage is Bayesianly natural
From a Bayesian point of view, shrinkage happens because the prior says that very large coefficients are unlikely. The posterior combines this prior information with the evidence in the data.
This often improves prediction, especially in noisy or high-dimensional settings.
Note
In machine learning language: regularization controls overfitting.
In Bayesian language: priors regularize estimation.
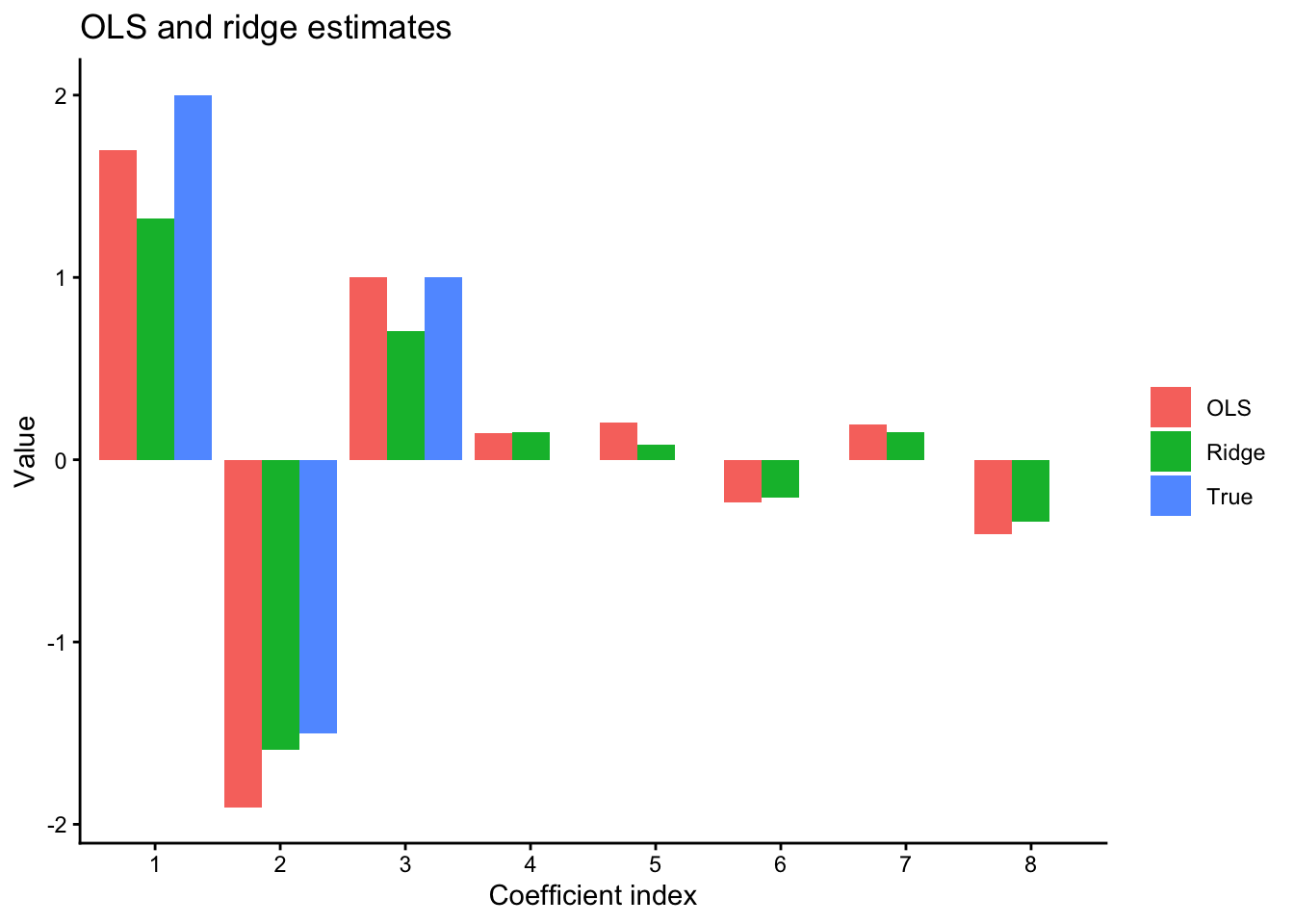
8.5 A simple simulation: ordinary least squares versus ridge-style shrinkage
The following example illustrates the effect of shrinkage in a small regression problem.
Figure 8.1: Comparison of ordinary least squares and ridge regression coefficient estimates in a small simulated example.
8.6 Discussion of the plot
In many small or noisy datasets, the ordinary least squares estimates can be unstable. Ridge shrinkage tends to pull the estimates toward zero. This can reduce variance and improve predictive performance, even if it introduces some bias.
This is a good example of a more general machine learning principle:
A small amount of bias can be worthwhile if it substantially reduces variance.
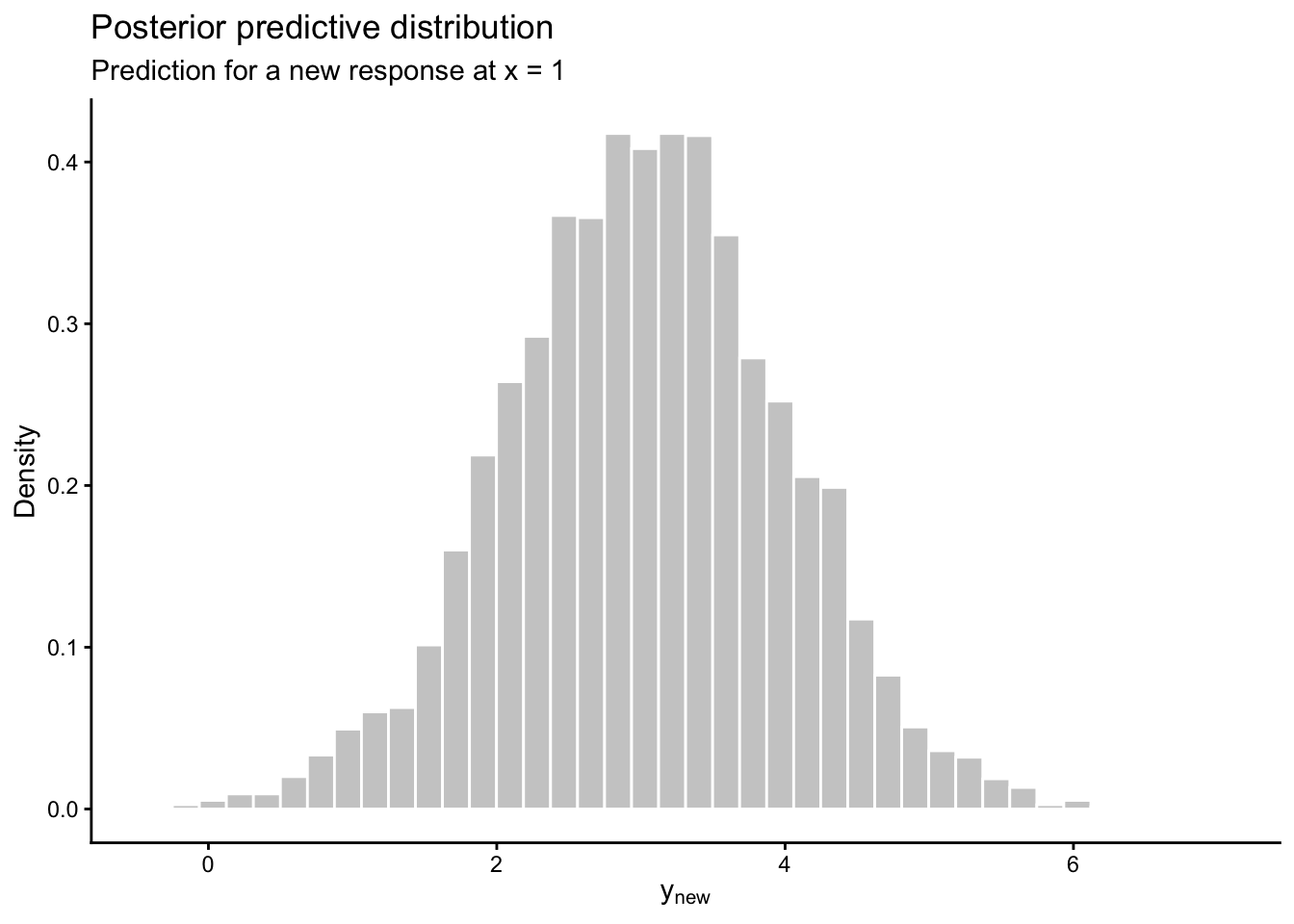
8.7 Prediction and uncertainty
A major strength of Bayesian methods is that prediction is naturally probabilistic.
Suppose we have a new predictor vector \(\mathbf{x}_{\text{new}}\). In a non-Bayesian regression analysis, we may plug in an estimate and compute
Many machine learning models make predictions, but not all provide uncertainty in a principled way.
Bayesian models naturally provide:
predictive distributions,
credible intervals,
probabilities of events.
This is particularly important in applications such as:
medicine,
policy,
finance,
scientific prediction.
8.11.3 3. Model complexity and overfitting
Bayesian methods can control complexity through the prior. Instead of just asking
Which parameter values fit the data best?
Bayesian analysis asks
Which parameter values are plausible after combining prior structure with the observed data?
This can improve stability and generalization.
8.11.4 4. Modern computation
In simple models, posterior distributions may be available in closed form. In more complicated models, Bayesian machine learning relies on computational methods such as:
MCMC,
Hamiltonian Monte Carlo,
variational inference.
This is one reason Bayesian computation has become such an important part of modern statistics and machine learning.
8.12 Bayesian versus machine learning language
It is often helpful to translate between the two languages.
Machine learning language
Bayesian language
Regularization
Prior distribution
Training loss + penalty
Negative log posterior
Prediction
Posterior predictive distribution
Parameter estimate
Posterior summary
Ensemble / uncertainty
Posterior distribution over functions or parameters
Note
These are not exactly the same in every setting, but the parallels are often very strong.
8.13 What Bayesian methods add
It is worth emphasizing that Bayesian methods do not replace machine learning. Rather, they provide a probabilistic framework for many of the same goals.
Bayesian methods add:
principled uncertainty quantification,
coherent updating,
interpretable regularization through priors,
predictive distributions instead of only point predictions.
8.14 Summary
In this lecture, we explored several important links between Bayesian statistics and machine learning.
Main ideas:
Bayesian linear regression is a probabilistic predictive model.
Regularization can often be interpreted as prior modeling.
Posterior predictive distributions quantify uncertainty in predictions.
Many modern machine learning ideas have natural Bayesian counterparts.